Today: How Twitter processes billions of events in real time?

How Twitter processes billions of events in real time?
Over last decade, Twitter did several upgrades to the infrastructure to process data. The last was in 2015 when they built their own infra called Heron. You can call current update as 3rd generation!
TL;DR: Before 2021, they were using Lambda architecture and now they shifted to Kappa architecture. In Lambda architecture, both batch processing and real time processing are done separately. In Kappa architecture, both are done using same stack, together.
The old architecture looks as below

Batch Processing (processed in batches): Hadoop logs are ingested into Scalding pipelines (Scalding is a Scala library that makes it easy to manage MapReduce jobs), and after processing, they are sent to Distributed Database (data is stored across different locations).
Real time processing: Kakfa topics (topics are like tables but more flexibility) are processed by Twitter’s in-house Heron infra, and are stored in Distributed Cache (pooling RAM of multiple systems to be able to process real time data).
Data from both batch processing and real time processing are extracted by a query service and are served to consumer services.
All was good. What’s the issue then?
First: High latency. Batch processing had latency of around 1 day and Real time processing had latency of around 10 seconds to 10 min.
Second: Data loss and accuracy issues due to Heron, used to process real time. To understand the reasons, let us understand Heron a bit.
Following is a visual diagram

Heron has what’s called Spouts (S1) and Bolts (B1, B2, B3, B4).
Spouts (S1) emit data. Bolts (B1, B2 etc) process data.
Visualize it as like a assembly line - S1 is emitting data. B1, B2 etc. are processing data and moving it forward.
The problem is that when S1 emits more data than the B1, B2, etc can process, the data gets accumulated at S1 (increasing what’s called back pressure). The system slows down, creating a lag. Even if it is corrected, it takes lot of time to clear up the lag. Often, they had to restart the Heron containers but that leads to data loss.
What’s the new architecture?
In the new architecture (Kappa), both batch processing and real time processing are done together.
In summary, Kafka topics are processed by an event processor and are sent to Google Cloud. A query service fetches data from Google cloud and serves to consumer services.
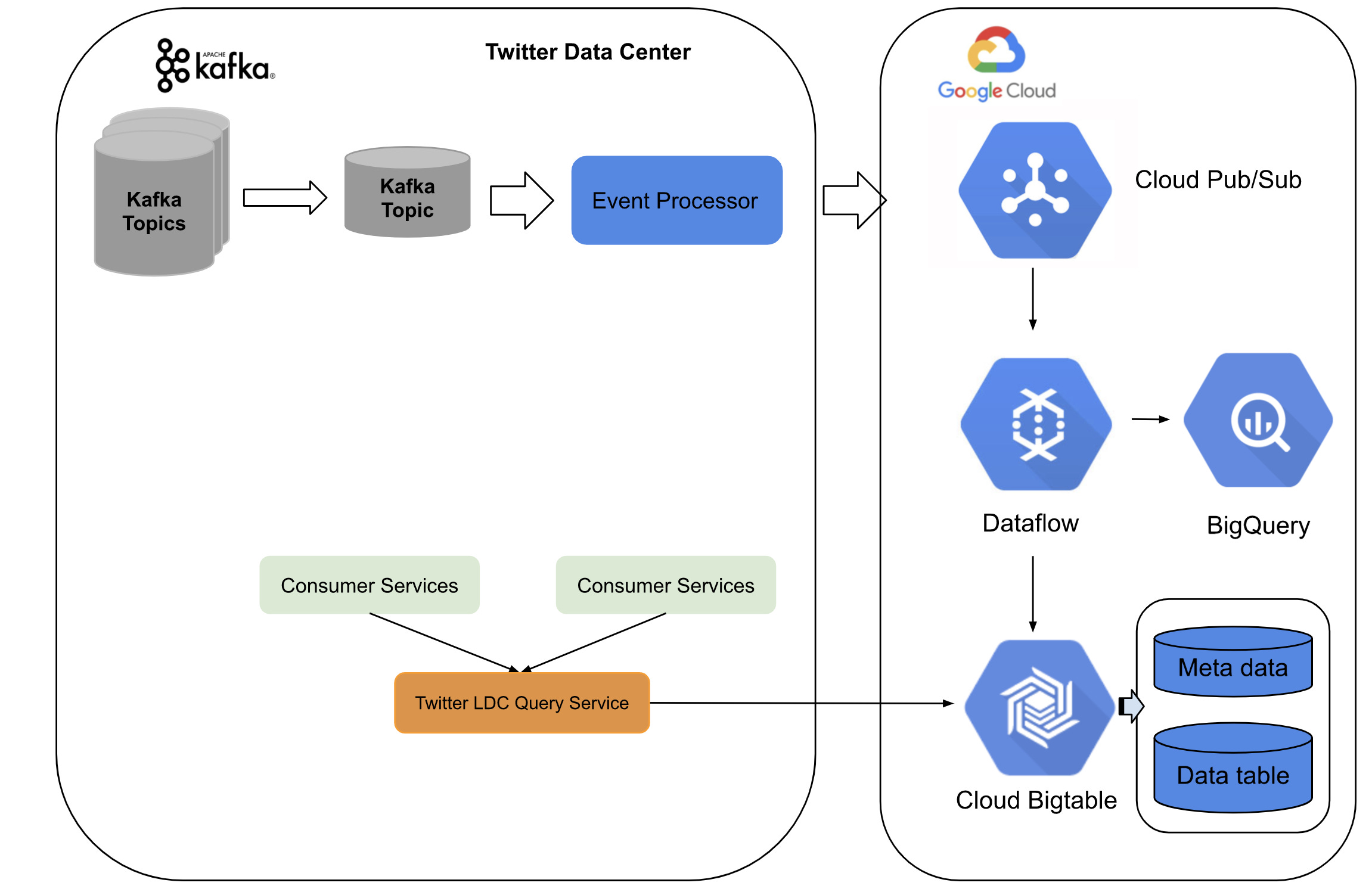
Let us understand the details of data flow before it enters Google Cloud, and the flow within Google Cloud.
Data flow before entering Google cloud
Data from different Kafka topics (topics are like tables but with flexibility) are pre-processed where some transformations are done and are converted to another Kafka topic.
The processed Kafka topic is sent to an Event Processor.
Event processor does 2 things
Converts Kafka topics to pub/sub events. Pub/Sub events are where a publisher sends event and are broadcasted to all subscribers. Publishing and Sending work asynchronously, thus giving more flexibility.
Generates event context consisting of UUID and other meta information related to processing context
Data is sent to Google Cloud in ‘at-least-once’ semantics. ‘At-least-once’ is a type of sending messages where it is ensured that message is sent at least once. Other types of sending messages are exactly-once, at-most-once etc.
To achieve ‘at-least-once’, they do infinite retries, using a setting in pub/sub event handling.
Data flow after entering Google Cloud
Because they used ‘at-least-once’ semantics earlier, there is a possibility of duplicates entering Google Cloud. So, they have to first remove the duplicates. They use a internal framework developed on DataFlow to remove the duplicates.
UUID and info on event’s context added by event processor earlier, helps in deduplication.After deduplication, data is written to Big Table.
A query services fetches data from Big Table and serves consumer services.
Impact: The latency of both types of data (batch and real time) is around 10 seconds, where as, earlier, it was 1 day for batch data and 10 seconds - 10 min for real time data. Also, the system is now more accurate and stable.
.Key terms:
Lambda architecture: Batch processing and Real time processing are done separately.
Kappa architecture: Batch processing and real time processing are done together
Kafka topics: Topics are like tables but with more flexibility.
Heron topology - Spouts, Bolts: Heron is Twitter’ internally developed framework. Spouts emit data. Bolts process data.
Pub/Sub events: A way of transmitting data where publisher sends data and is broadcasted to subscribers asynchronously.
At-least-once semantics: A way of sending messages where it is ensure that message is sent at-least-once. Other types are ‘exactly-once’, ‘at-most-once’ etc.
Distributed Cache: Pooling of RAM from multiple machines to do real time processing.
Tools/Frameworks
Scalding: Scala library that makes it easy to manage MapReduce jobs. Similar to Pig.
Heron: Twitter’s internal framework to process real time data, built on Storm.
SummingBird: Platform to implement Storm/Heron
Dataflow: Streaming analytics service
Big Query: fully-managed, serverless data warehouse that enables scalable analysis
Big Table: fully managed, scalable NoSQL database service for large analytical and operational workloads